robots.txtの書き方と設置方法
Googleなどの検索エンジンはリンクを辿ってサイトをクロールしインデックスしていきますが、robots.txtを使用すると検索エンジンに対してサイトの中の特定のファイルやディレクトリをクロールしないように要望を出すことができます。ここではrobots.txtの使い方と実際の記述方法について解説します。
(2022 年 04 月 22 日公開 / 2022 年 04 月 22 日更新)
目次
robots.txtとは
検索エンジンなどは検索エンジンロボットやクローラーと呼ばれるプログラムを使ってインターネットで公開されているサイトの情報を集めています。公開されているページはクローラーにクロールされることで検索エンジンに登録され(インデックスされるともいいます)、その結果として検索結果に表示されます。
通常は公開しているページに対するクロールをブロックする必要はないのですが、サイトの中には公開はしているけれど検索結果には表示を希望しないページがある場合があります。またCMS(コンテンツマネージメントシステム)などを利用されている場合にはページを自動的に生成するものがあり、このような自動生成されたページにはクロールが行われない方が望ましい場合があります。
このように検索エンジンなどのクローラーに自分のサイトの一部をクロールして欲しくない場合にrobots.txtを作成します。必要なければrobots.txtは必須ではありません。ただクローラーは一応robots.txtが無いかどうか探すため、ブロックが無い場合でもrobots.txtだけは作っておいたほうがいいかもしれません。
robots.txtの名前と設置場所
robots.txtを利用する場合、作成するファイルはテキストファイルで作成し、ファイルの名前は必ず「robots.txt」とする必要があります。文字コードはUTF-8で保存して下さい。またrobots.txtはサイトのルートディレクトリに設置する必要があります。サブディレクトリなどに設置しても認識されません。
○ http://www.example.com/robots.txt × http://www.example.com/dir/robots.txt × http://www.example.com/myrobot.txt ○ http://example.com/robots.txt ○ http://sub.example.com/robots.txt
また設置したrobots.txtへクローラーがアクセスできなければいけません。その為、robots.txtへのアクセスが制限されていないように注意して下さい。
robots.txtの書き方
robots.txtには、(1)どのクローラーに対して(2)どのファイルやディレクトリのクロールをブロックするのか、を記述していきます。例えば全てのクローラーに対して全てのページのクロールを許可する場合は次のように記述します。
User-Agent: * Disallow:
ではそれぞれの項目について詳しく見ていきます。
User-Agent
まず最初に「User-Agent」を使って対象となるクローラーを指定します。クローラーは検索エンジンが主に使用しますが、他のサイトの情報を集めてまとめて公開しているようなサイトなども独自のクローラーを使っている場合があります。また例えばGoogleだけでもウェブ検索用や画像検索用、そしてAdSense用など複数のクローラーを動かしています。
・Google クローラ - Search Console ヘルプ
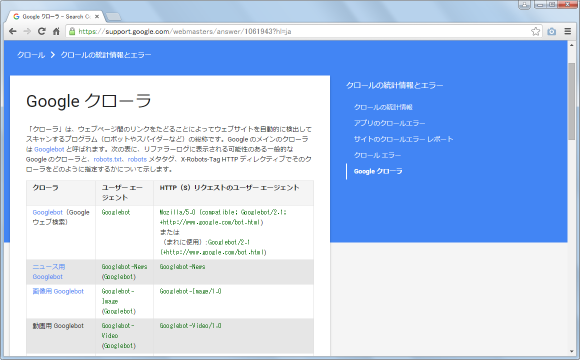
robots.txtでは「User-Agent: 」の後に対象となるクローラーの名前を記述します。名前は各クローラーで決まっており特定のクローラーに対する制限を行うには、まずクローラーの名前を調べる必要があります。
Googleのウェブ検索クローラーに対して全てのファイルのクロールをブロックする場合は次のように記述します。
User-Agent: Googlebot Disallow: /
Bingのクローラーに対して全てのファイルのクロールをブロックする場合は次のように記述します。
User-Agent: bingbot Disallow: /
GoogleやBingなど複数のクローラーを対象にする場合は、それぞれ別々に記述します。複数のクローラーに対して記述する場合は続けて記載しても構いませんが、分かりやすいように間に1行空けて書かれる場合が多いようです。
User-Agent: Googlebot Disallow: / User-Agent: bingbot Disallow: /
特定のクローラーではなく全てのクローラーを対象とする場合は特別な文字「*」を指定します。次の例では全てのクローラーに対して全てのファイルのクロールをブロックしています。
User-Agent: * Disallow: /
Disallow
次に「Disallow」を使ってクロールをブロックするファイルやディレクトリを指定します。前提として明示的に禁止しないものについて全てクロールが許可されたことになっています。その上でクロールをブロックするファイルやディレクトリを指定していくことになります。
まず最初にブロックを一切しない場合の例です。全てのファイルのクロールを許可する場合は次のように「Disallow: 」の後に何も記述しません。
User-Agent: * Disallow:
最初に記載した通り何も書かなければ全て許可されているので書く必要性はありません。それでもブロックをしていないことを明示的に表すためにこの2行だけを記載しているケースは多いです。
続いてクロールを禁止する場合の記述方法です。全てのファイルをブロックする場合は「/」を記述します。
User-Agent: * Disallow: /
指定したディレクトリとディレクトリに含まれる全てのファイルをブロックする場合は「/」の後にディレクトリ名を記述します。このディレクトリに含まれる子ディレクトリなども全てブロックされます。
User-Agent: * Disallow: /dir/
(ブロックされるURL) www.example.com/dir/ www.example.com/dir/index.html www.example.com/dir/img.png www.example.com/dir/subdir/index.html
最後の「/」がない場合、「dir」で始めるファイルやディレクトリが全てブロックされます。
User-Agent: * Disallow: /dir
(ブロックされるURL) www.example.com/dir/ www.example.com/directory/ www.example.com/dir.html www.example.com/dirfriend.html
複数のディレクトリをブロックする場合は「Disallow」の行を複数続けて記述します。
User-Agent: * Disallow: /temp/ Disallow: /test/ Disallow: /user/
(ブロックされるURL) www.example.com/temp/ www.example.com/user/img/phpto.png www.example.com/test/index.html
サブディレクトリを指定する場合は、「/」の後に親ディレクトリも含めて子ディレクトリの名前を記述します。
User-Agent: * Disallow: /my/dir/
(ブロックされるURL) www.example.com/my/dir/ www.example.com/my/dir/index.html
Disallowのパターンマッチング
「Disallow」では「*」と「$」の2つのパターンマッチングが使用できます。「*」はワイルドカードとして使用できます。「$」を最後に付けるとURLの末尾とマッチします。
全てのディレクトリにある特定の拡張子のページをブロックする場合、「/」の後に最初に「*」最後に「$」を付けた拡張子名を記述します。下記は任意の文字列が続いた後に「.php」という拡張子がURLの末尾にあるファイルがブロックされます。
User-Agent: * Disallow: /*.php$
(ブロックされるURL) www.example.com/index.php www.example.com/my/dir/homepage.php
特定のファイル名のページをブロックする場合も先ほど同じように「/」の後に最初に「*」最後に「$」を付けたファイル名を記述します。
User-Agent: * Disallow: /*filename.html$
(ブロックされるURL) www.example.com/filename.html www.example.com/my/dir/filename.html
Allow
「Allow」は「Disallow」とは逆にクロールを許可するファイルやディレクトリを指定します。単独で使用することはあまりなく「Disallow」でブロックした中の一部を許可するために使用します。対象となるファイルやディレクトリの指定の仕方はDisallowと同じです。
例えば「Disallow」を使って指定したディレクトリとそこに含まれる全てのファイルをブロックした後、そのディレクトリに含まれる特定のファイルだけクロールを許可したい場合には次のように記述します。
User-Agent: * Disallow: /dir/ Allow: /dir/sample.html
上記の場合は「dir」ディレクトリに含まれるファイルは全てブロックされますが、「/dir/sample.html」ファイルだけはクロールが許可されます。(次の優先順位参照)。
複数のレコードが記述された場合の優先順位
「Allow」や「Disallow」などのレコードが複数記述されていた場合、どのレコードが優先されるのかについてはGoogleの公式ページには次のように記載されています。
グループ メンバー レベル、特に allow および disallow ディレクティブでは、[path] エントリの長さに基づいて、最も限定的なエントリが、限定的でない(短い)ルールよりも優先されます。ワイルドカードを含んだルールの優先順位は定義されていません。
[path] エントリというのは「Disallow: 」や「Allow: 」の後に記載されている部分のことです。より限定的な対象について記載されたものが優先順位が高くなります。下記では「Disallow: 」がディレクトリ全体をブロックしているのに対して「Allow: 」はそのディレクトリの中の一つのファイルだけについて許可していますので「Allow: 」の方が優先されます。
User-Agent: * Allow: /dir/sample.html Disallow: /dir/
-- --
robots.txtファイルの記述の仕方について解説しました。robots.txtには今回のようにクロールの制限に関する記述だけでなくサイトマップの場所を記述することもできます。これについては「robots.txtファイルでサイトマップの場所を指定する」を参照されて下さい。
( Written by Tatsuo Ikura )

著者 / TATSUO IKURA
プログラミングや開発環境構築の解説サイトを運営しています。